We’re nearing a major release of the MarkLogic C++ REST API. Read on for details…
As many know it’s long been an ambition of mine to greatly widen the programming language specific API bindings for the MarkLogic REST API.
This makes talking to MarkLogic Server in a developer’s own language as easy just calling a function in any other library.
I’ve already created JavaScript (Node.js and Browser), C#.NET, and now a C++ API with a fellow MarkLogician’s great help, Paul Hoehne.
We’ve been working on this library for over a year in our copious(!) free time. The library uses Microsoft’s excellent cross platform – and open source (shocker!) – cpprest SDK, what was called Casablanca. This is available on Microsoft’s GitHub account… which is a sentence I still can’t believe I’m writing!
This major release of mlcplusplus will provide a middle-layer over the top of the existing low level REST (Authenticating Proxy) layer to provide simple function calls for many MarkLogic functions.
The first functions I’m concentrating on are saving, modifying, and retrieving documents in JSON and XML. The search and getDocument functions are already shelled out and working.
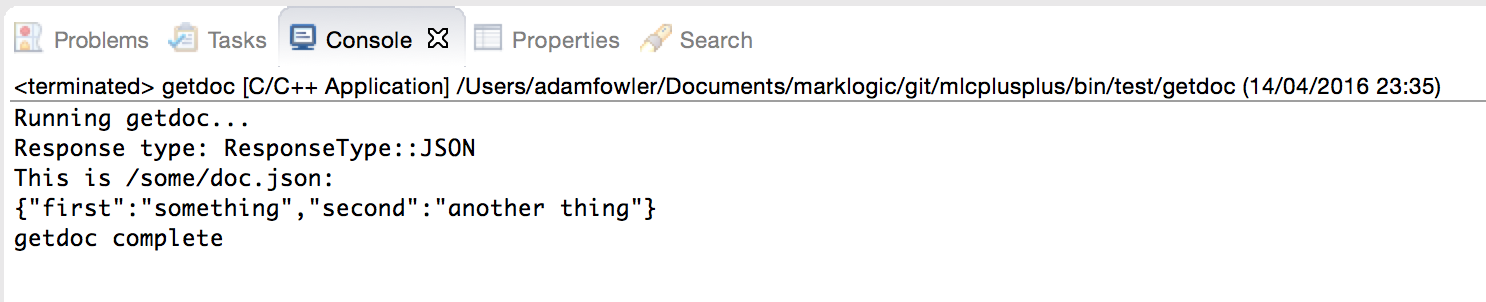
Below is an image of the first test app we’ve created. It’s not the prettiest, but it’s only a quick test app consisting of about 5 lines of code!
The library will also provide common utility functions, including generating a C struct from a set of documents to allow for easy marshalling/unmarshalling, a set of C functions to link our C++ library to a legacy C application, and possibly a search query builder helper class too.
We also want to create a very fast way to batch import files using this library – so look out for that in future! Initial laptop testing shows performance equivalent or slightly faster than the MLCP (Content Pump) data loading tool.
After this the world is our oyster… problem is, it’s a big world! We need customers, partners, and general tinkerers to help guide us as to what’s important to pursue for the next set of features.
Do we provide a C++ layer over the triple store too? Concentrate on object-to-XML/JSON persistence? Or just concentrate on fast loading of data? Do you want a brew/rpm/nuget package?
Please let us know what you want by submitting Enhancement requests to the project’s issue tracker: https://github.com/adamfowleruk/mlcplusplus/issues
Thanks in advance for all your help!
