In this roundup post I show details of all the widgets available both in Application Builder and in my MLDB JavaScript API…
I’ve been developing MLDB in isolation for the last couple of months, so I thought it would be useful to put a roundup of what I’ve delivered in that. I also thought it may be instructive to show what you get out of the box in MarkLogic 6’s Application Builder too.
Application Builder
App builder as we often call it is a wizard driven web based tool for getting up and running quick with a search application on MarkLogic. Once you have configured your indexes and loaded content (probably using Information Studio’s wizard tools for that), you use App builder to build a quick application on top of it.
The process is quite straightforward – you review the indexes on your database given them readable names, you define the facets available for your application, you specify how search result summaries should look, then you say which widgets (high charts graphs, google maps) you wish to use, then you preview the layout of this. When done, you deploy the whole app to a new REST API server that the wizard can create for you.
Here’s a screenshot of the search config and indexes page in App Builder for some publicly available NHS prescription information:-

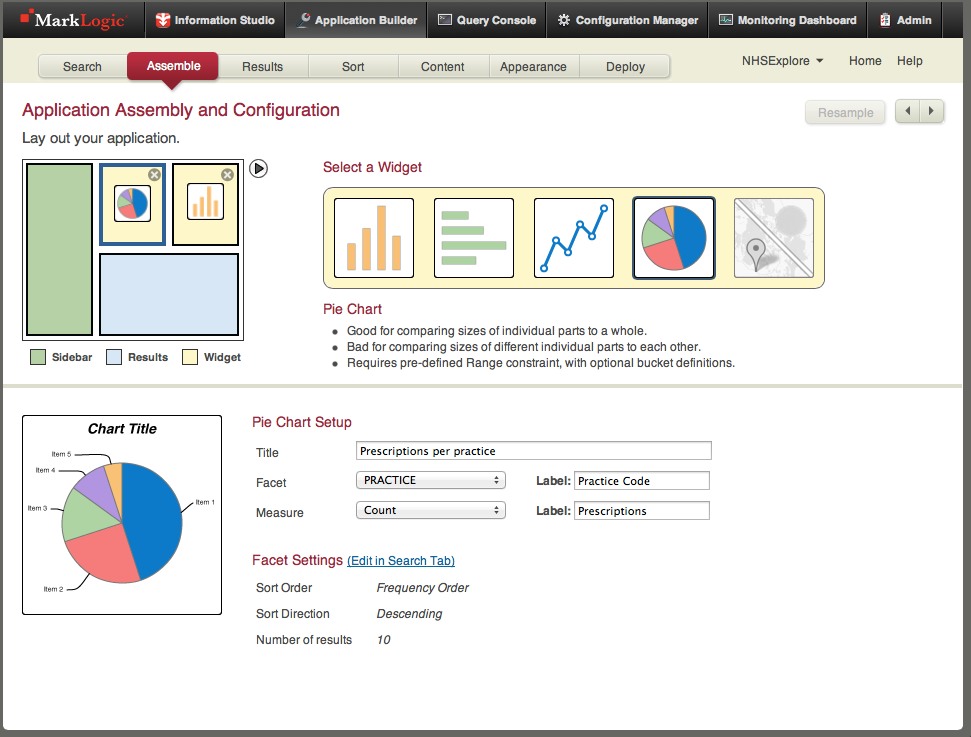
Also the layout page showing a couple of widgets, and one of these widget’s configuration:-
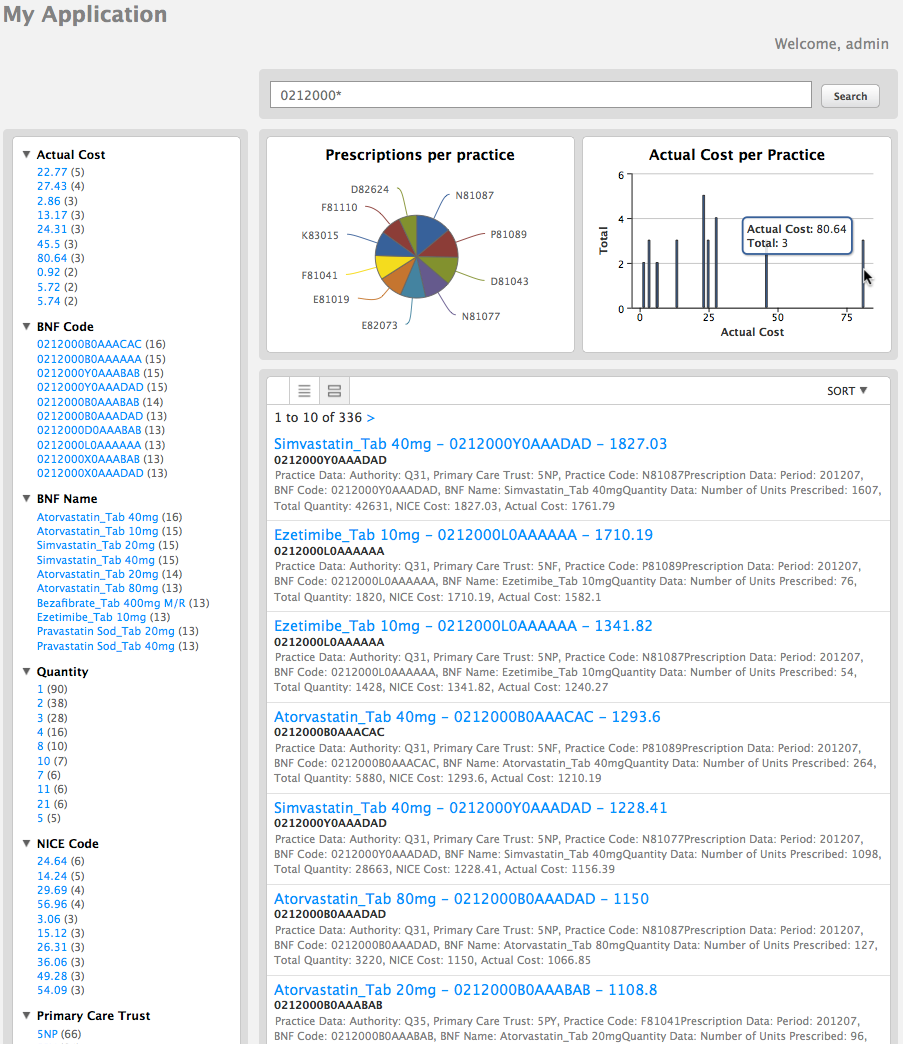
This can be used to create a working, valuable search application like the one below that shows a chart of the total number of prescriptions across a range of prices:-
Widgets in app builder
The App Builder provides a standard set of search functionality – search bar, facet navigation, sorting, results pagination, and the result list itself. It also allows you to embed 1 or 2 visualisation widgets between the search bar and the results information. These can be HighCharts based graphs or google maps, with heatmaps. The data for these visualisations is gathered from aggregations defined in the search options or from facet information.
This search page is a great starting point. There are a couple of downsides. The first is that App builder doesn’t yet support Path Range indexes that were added in V6. The second is that the use case is for a search app only – there’s no support for getting the data in or doing something with the search results (E.g. download an Excel summary)
Customising app builder
You can customise the app builder but it is non trivial. Depending on what you are doing you sometimes need to work in XQuery, or XSLT or JavaScript – often in a mix of them. This isn’t great if you’re a web developer creating an enterprise app.
Adding customisations is supported within a ‘custom’ folder, but unless you know what you are customising exactly it’s hard to get your head around. The search results are rendered using XSLT, and interaction is handled in a complex controller.js file.
It must be noted that when I’ve tried (or some of my colleagues) to alter app builder it’s not been a fun experience. Often it takes a lot of time. Also, even when done, if you were taking the application beyond a simple ‘suck it and see’ test / proof of concept, you’d rapidly need more functionality and an extensible, pluggable code base with a variety of functionality, which you could modify just in JavaScript (i.e. all UI work is ‘client side’. This is where MLDB comes in.
MLDB JavaScript API for MarkLogic
I wrote this originally as a Node.js JavaScript library, but I’ve since added in browser support. Naturally the next extension was to create a few UI widgets to visually expose that functionality in the browser. I’ve created a load of these:-
Search page
This is an overarching widget containing several other widgets. Below you see the default layout. This includes a search bar at the top, facets on the left. You see for the results a results pager, sorter and the results themselves. These are clickable too if you provide an app URL to handle navigation in the results widget.
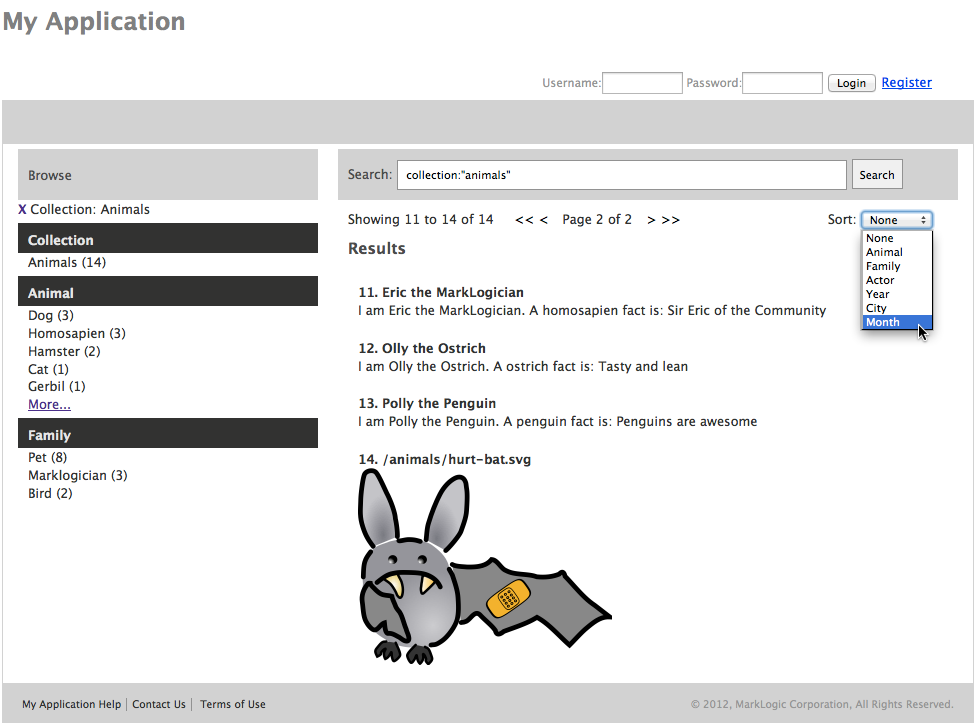
This page is intended to be very similar to the App Builder default app. How results are rendered is customisable – for example in the above most animals are JSON documents, whereas the bat is an SVG XML document. These renderers are pluggable at runtime.
I can also link a chart to the results. At the moment this is limited to only the search results on the page because the graphs are linked to JSON docs’ contained properties rather than to search values or facets summaries. I’ll change this in future though. I’ll also allow embedding in the search-page widget too. Below is a couple of charts linked to a search bar as a simple example.

Charts
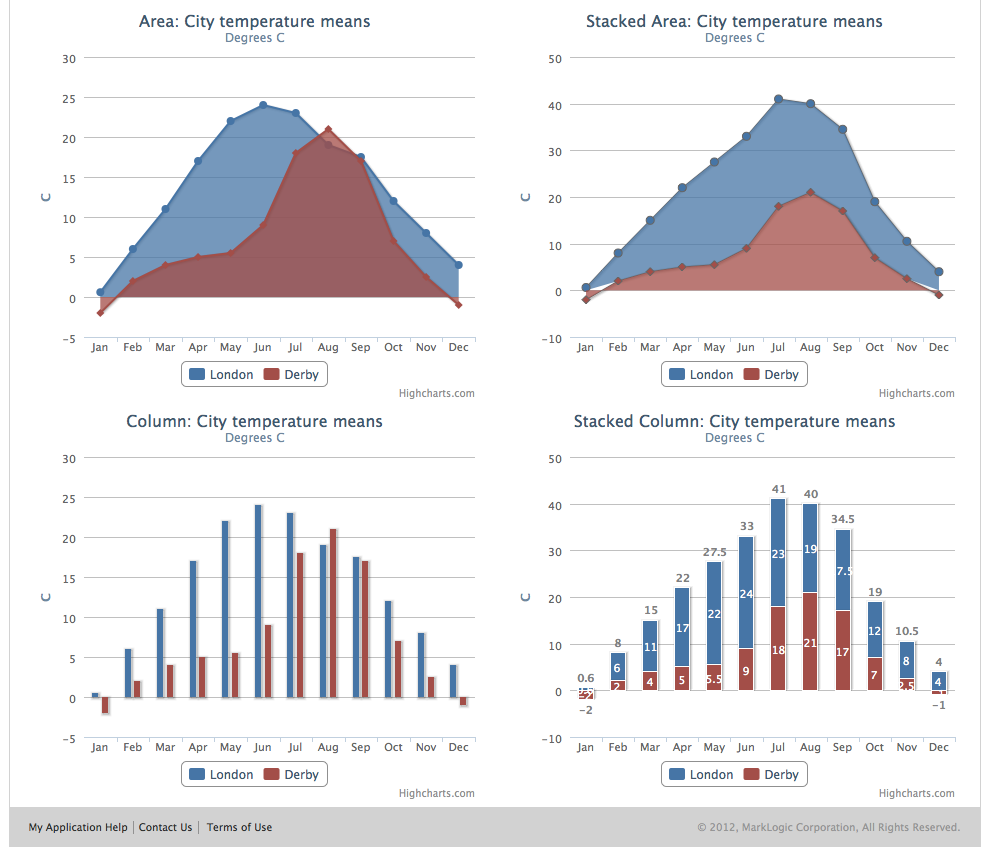
There are a host of different charts available. Below are a few examples. MLDB is a thin wrapper over the HighCharts library that comes with MarkLogic, so any chart you can create should ‘just work’. Famous last words. Here are a few examples:-

And these:-
Co-occurence
Co-occurence is a great way to find previously unknown links. Say you extracted product names, medical conditions, and adjectives from a set of twitter posts. You could add co-occurences to see what ailments are linked to which product, or to see which adjectives are linked to which product (E.g. ‘sucks’ and ‘awesome’). You could also see which products are mentioned together (product-product co-occurence). A very useful way to find links. Here’s the pure HTML+JavaScript widget:-
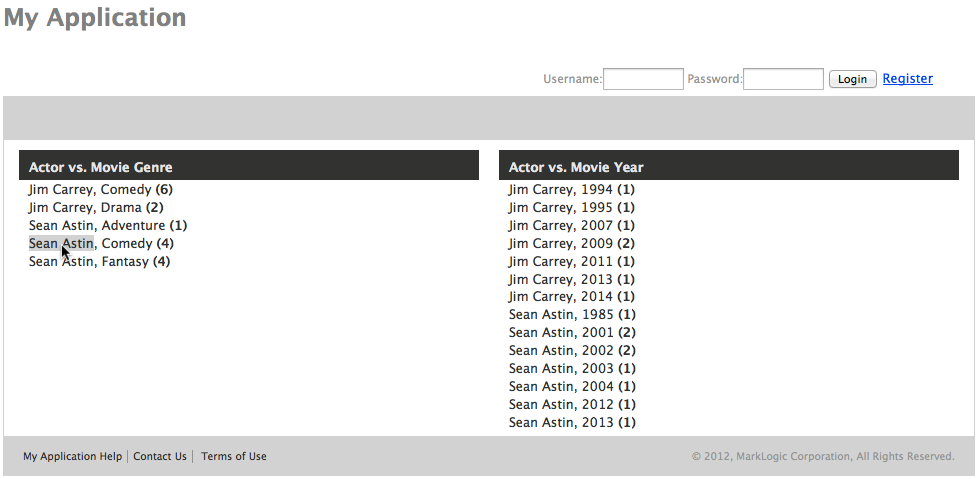
In this example I’ve put in movie information. Two co-occurences are provided – one of main star against movie type, the other of star against year of release. You see here that Jim Carrey mainly works in comedy, whereas Sean Astin has worked in a variety of films (Goonies, LoTR, and recently in an episode of NCIS!)
File upload (Docbuilder)
One of the things we tend to overlook in pre-sales is the addition of new documents. We tend to bulk load sample docs using command line tools. Fine for a demo, but not great for an actual end user on a production system.
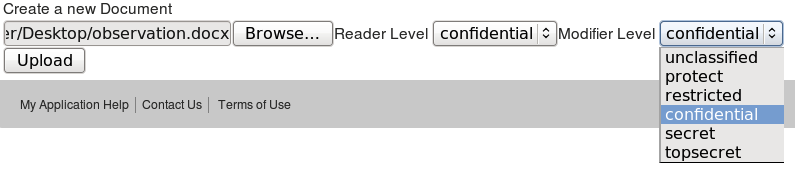
I’ve added a docbuilder widget. The idea behind this is that you can build up a HTML form to create a new document by adding fields and linking them to XML or JSON fields. All from simple function calls on a widget object – no nasty form code required. At the moment though I’ve only had time to add basic file upload and permissions controls – so you can specify a single file, it’s URIs pattern, collections, and it’s read and update properties. All works fine and dandy:-
Markings / adding facts (triples)
Something that may occassionally be useful is embedding security markings within an XHTML document. Maybe most of a report can be read by some people, but the section detailing next steps is classified at a higher grade. You can do this in MarkLogic by using an XQuery transformation on all get and search operations. This effectively redacts sections on the fly. Very neat feature.
In MarkLogic 7, which is currently in Early Access, we support storing triples in the server. These are facts in subject-predicate-object triples. E.g. Adam Likes Cheese. Getting to a point where these are extracted and linked is non trivial. I decided to use any entities identified in the XHTML (E.g. by Temis, Smartlogic or by a simple DB trigger in my examples) and use their existence in the same paragraph to suggest triples.

So from the above you see that Abraham Troublemaker and Animal Freedom are mentioned in the same paragraph, so my code suggest that A Troublemaker is a member of the Animal Freedom organisation. The user can remove, modify or add to these facts. Clicking on done adds security to the relevant document sections, but also stored the facts in to MarkLogic, and maintains a link from those fact graphs back to their originating document and section.
SPARQL (facts query) widgets
Having triples stored is one thing (see above), but querying them is another. There is a W3C standard called SPARQL. This is kinda like SQL but is a lot more flexible. Complex queries may be hard to understand though. I’ve created a widget so you can define these queries using object hierarchies. In the below example I search for any people that are members of an organisation with the name Animal Freedom.

As you can also see, you see a summary of results. Clicking on one of these views all the facts for that entity in the triple store. An extension I’ve not yet done is clicking a ‘related content’ button on this facts list so you see the list of documents that these facts were inferred from. Each of these three is a separate widget (Indeed the content results widget is the same one as on the search page example, higher in this article – showing re-use of widgets).
Collection URIs
It is sometimes useful to view a collection’s child collections. For now I’ve created a simple list. A tree structure could also be useful. No image yet, sorry! It’s just a simple list of names anyway right now.
Google Kratu
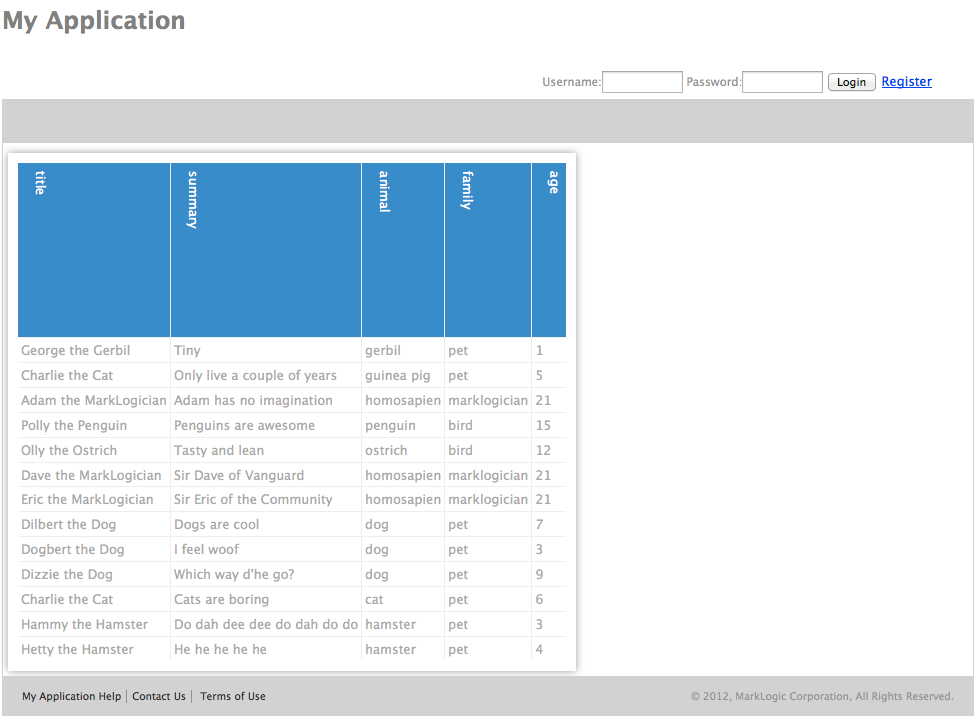
Kratu is a handy little widget for visualising JSON results – it can take any results and view them in a tabular format. I’ve created a thin wrapper widget that links JSON search results to Kratu. You can choose either the documents’ content (default) or the search parameters (URI, match score for each doc – for example)
The future
I’m currently working on a set of widgets for Records Management using the Document Library Services (DLS) functionality of MarkLogic. I can already declare search results are records. I will extend this to support listing of RM collections, and RM rules.
Conclusion
The world is your oyster when it comes to UI – and everyone’s needs are different. I have found it best to be very flexible in providing a granular set of widgets that can be used together using a common data model (MarkLogic REST JSON objects). I have already created a set of apps much quicker using re-usable content rather than coding from scratch in XQuery. I can then spend my time on novel functionality for each of our clients.
Creating a search page application in MLDB requires installing Roxy, then MLDB, then writing around 8 lines of JavaScript. Easy, but still takes some time. The advantage is that once you go beyond the first search page then customising your app becomes a case of using JavaScript 99% of the time.
If what you want is a quick search app over new data, then try App Builder. This will get you a visualisation quickly at the cost of long term extensibility later on.
All the above functionality is available for MarkLogic 6 except any semantic/triple functionality which requires ML 7 Early Access. You can get MLDB from here. Read the README text at the bottom of the page.

One comment