I’ve been building sample demonstrations for the upcoming MarkLogic 7 release which features a triplestore and SPARQL and Graph Store endpoints. I’ve been experimenting with taking in any content (E.g. Word document) and identifying objects and facts. Read this article to find what I’ve been up to…
Disclaimer
I want to point out that in all screen shots the names of the people are fictitious, as is the organisation ‘Animal Freedom’. The only reason I’ve used some real place names and organisations is so I can link them to publicly available RDF information in future editions of my demonstration (E.g. dbpedia or geonames). The data used is made up. The reason for picking these locations is that the area is familiar to me, thus making the demonstration easy to remember.
Aim of the work
We talk a lot in MarkLogic about ingesting data ‘as is’ but also around entity extraction and enrichment. This means identifying things like people, place and organisation names, and perhaps adding (enriching) extra information such as longitude/latitude, as well as what type of object that text describes.
I wanted to take that idea and put a semantic twist on it. So given the presence of a person and organisation in the same paragraph, what are the possible relationships between those? Which is most likely? Then suggest to the user these facts for modification or removal.
This is to aid the publishing process going from source data, through enriched data, and ready for the creation of Linked Data of your own for later publication or internal use. At the moment I’m concentrating on the internal use aspects.
How to create the links
First of all I use a database trigger to convert binary documents to XHTML ones, and maintain a link to the original. I then process this XHTML to identify known people, places and organisations and place a tag around that text. E.g. Walkley becomes <placename>Walkley</placename>. This is a simplified example of what you would do in real life. MarkLogic has several partners including Smartlogic, Temis and TSO (aka Williams Lea) that provide these pluggable services.
I then have a JavaScript widget based on my MLDB JavaScript API for MarkLogic that, amongst other things, extracts XML nodes that it recognises as object types – Person, Place, Organisation. It also suggests triples based on proximity of these elements to each other. Here’s what it looks like:-

So you see the content on the left split in to sections with headings automatically by the widget. You see the suggested facts for human modification on the right of the relevant section.
When you hit ‘publish’, as well as updating the document with changes, facts (triples of subject, predicate and object) are added in to MarkLogic 7. Here’s an example of the first section with content, above, in N-triples format (Subject-Predicate-Object on each line):-
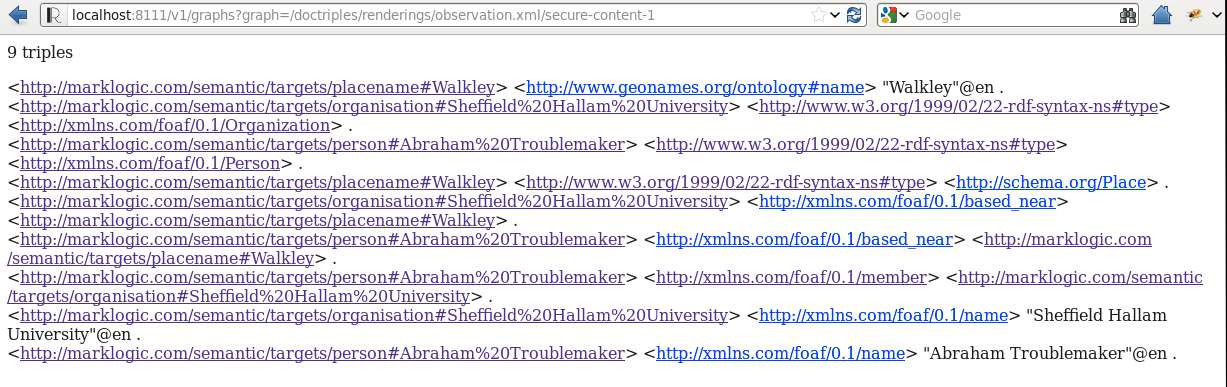
As you can see, this defines the objects and facts about those objects, and the relationship between objects.
If you hit the MarkLogic 7 REST API endpoint directly, you can browse through the ‘things’ defined:-
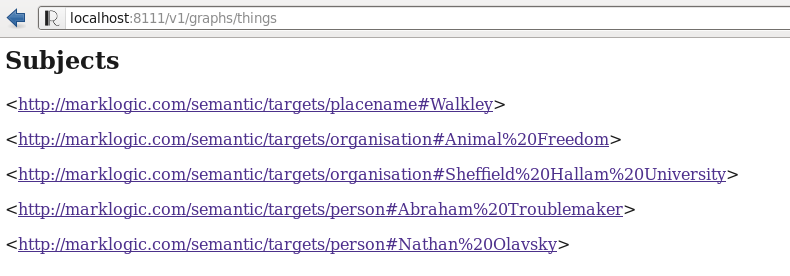
Here you see the place, organisations and people mentioned in the ingested document.
You can click on one of these people to see all the facts collected about that person, no matter through which section, or indeed document, in the system these facts were derived from:-

How do I use this?
This is where the next part of the demonstration comes in. Lets say you want to find all members of organisations you know about in Sheffield. Walkley is within the city of Sheffield, and Organisations are based in Sheffield, and they have members of type Person.
You can construct a SPARQL query to execute over your entire graph. This differs from a traditional search where you are looking for single documents that match your criteria. Instead, you search for objects and facts and relationships that match your criteria. This then gives you a resultant list. In this example Person objects. If you want, you can then view where these facts came from (i.e. source documents), or perhaps pull back any documents where these things are mentioned together.
Really though once you start adding these individual facts, webs of relationships start to emerge. You can use this to browse through your entire corpus of data, or to power discovery applications, or even publishing workflows.
In Conclusion
Semantic technology is a hot topic at the moment. People are trying to use NoSQL databases to manage unstructured data. You can use triple stores and named graphs to map dynamic relationships between objects, including documents or things mentioned within them, in the same way. The difference is, with a NoSQL document database and graph store combined, you can do all this dynamically with very little up front work, unlike with a traditional relational database based system.
A list of possible use cases for both NoSQL databases and Triple stores:-
- Answer ‘What do we as an organisation know about X?’
- Track where results came from in source research material
- Manage complex dynamic relationships, E.g. across website links and social media
- Provide a more meaningful and rich search experience – search meaning rather than just terms
- As a basic for readying internal information for Linked (Open) Data publishing
To find out more
If you’re interested in ML 7 then please contact myself at adam dot fowler at marklogic dot com. I can sign you up for our Early Access programme and put you in contact with local consultants working on the same problems.
